Documentation
Welcome to llmaz
llmaz (pronounced /lima:z/), aims to provide a Production-Ready inference platform for large language models on Kubernetes. It closely integrates with the state-of-the-art inference backends to bring the leading-edge researches to cloud.
High Level Overview
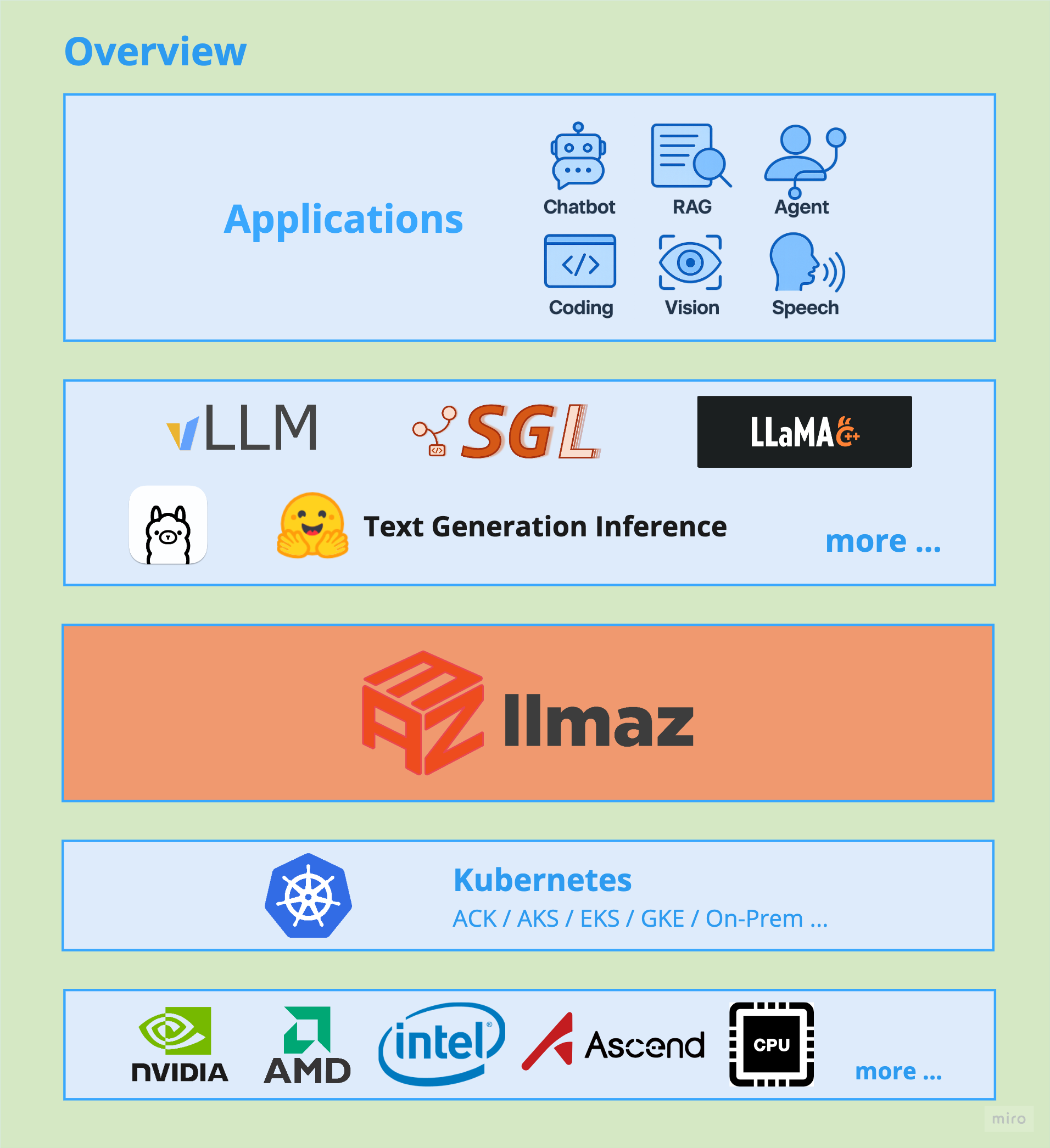
Architecture
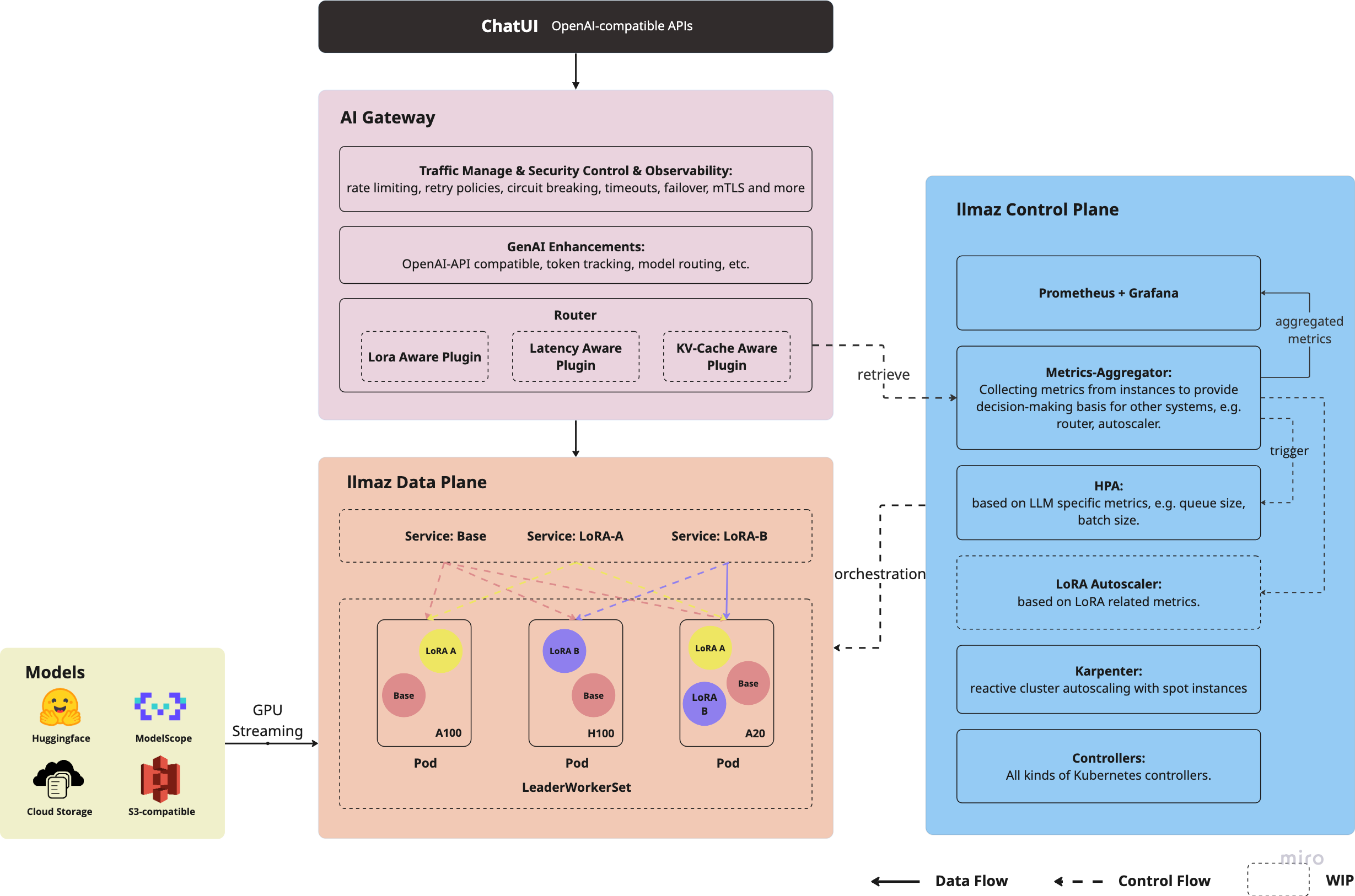
Read to get started?
1 - Getting Started
This section contains the tutorials for llmaz.
1.1 - Prerequisites
This section contains the prerequisites for llmaz.
Requirements:
Kubernetes version >= 1.27.
LWS requires Kubernetes version v1.27 or higher. If you are using a lower Kubernetes version and most of your workloads rely on single-node inference, we may consider replacing LWS with a Deployment-based approach. This fallback plan would involve using Kubernetes Deployments to manage single-node inference workloads efficiently. See #32 for more details and updates.
Helm 3, see installation.
Note that llmaz helm chart will by default install:
- LWS as the default inference workload in the llmaz-system, if you *already installed it * or want to deploy it in other namespaces , append
--set leaderWorkerSet.enabled=false to the command below. - Envoy Gateway and Envoy AI Gateway as the frontier in the llmaz-system, if you already installed these two components or want to deploy in other namespaces , append
--set envoy-gateway.enabled=false --set envoy-ai-gateway.enabled=false to the command below. - Open WebUI as the default chatbot, if you want to disable it, append
--set open-webui.enabled=false to the command below.
1.2 - Installation
This section introduces the installation guidance for llmaz.
Install a released version (recommended)
Install
helm install llmaz oci://registry-1.docker.io/inftyai/llmaz --namespace llmaz-system --create-namespace --version 0.0.10
Uninstall
helm uninstall llmaz --namespace llmaz-system
kubectl delete ns llmaz-system
If you want to delete the CRDs as well, run
kubectl delete crd \
openmodels.llmaz.io \
backendruntimes.inference.llmaz.io \
playgrounds.inference.llmaz.io \
services.inference.llmaz.io
Install from source
Change configurations
If you want to change the default configurations, please change the values in values.global.yaml.
Do not change the values in values.yaml because it’s auto-generated and will be overwritten.
Install
git clone https://github.com/inftyai/llmaz.git && cd llmaz
kubectl create ns llmaz-system && kubens llmaz-system
make helm-install
Uninstall
helm uninstall llmaz --namespace llmaz-system
kubectl delete ns llmaz-system
If you want to delete the CRDs as well, run
kubectl delete crd \
openmodels.llmaz.io \
backendruntimes.inference.llmaz.io \
playgrounds.inference.llmaz.io \
services.inference.llmaz.io
Upgrade
Once you changed your code, run the command to upgrade the controller:
IMG=<image-registry>:<tag> make helm-upgrade
1.3 - Basic Usage
This section introduces the basic usage of llmaz.
Let’s assume that you have installed the llmaz with the default settings, which means both the AI Gateway and Open WebUI are installed. Now let’s following the steps to chat with your models.
Deploy the Services
Run the following command to deploy two models (cpu only).
kubectl apply -f https://raw.githubusercontent.com/InftyAI/llmaz/refs/heads/main/docs/examples/envoy-ai-gateway/basic.yaml
Chat with Models
Waiting for your services ready, generally looks like:
NAME READY STATUS RESTARTS AGE
ai-eg-route-extproc-default-envoy-ai-gateway-6ddcd49b64-ldwcd 1/1 Running 0 6m37s
qwen2--5-coder-0 1/1 Running 0 6m37s
qwen2-0--5b-0 1/1 Running 0 6m37s
Once ready, you can access the Open WebUI by port-forwarding the service:
kubectl port-forward svc/open-webui 8080:80 -n llmaz-system
Let’s chat on http://localhost:8080 now, two models are available to you! 🎉
2 - Features
This section contains the advanced features of llmaz.
2.1 - Broad Inference Backends Support
If you want to integrate more backends into llmaz, please refer to this PR. It’s always welcomed.
llama.cpp
llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide variety of hardware - locally and in the cloud.
ollama
ollama is running with Llama 3.2, Mistral, Gemma 2, and other large language models, based on llama.cpp, aims for local deploy.
SGLang
SGLang is yet another fast serving framework for large language models and vision language models.
TensorRT-LLM
TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and support state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM also contains components to create Python and C++ runtimes that orchestrate the inference execution in performant way.
Text-Generation-Inference
text-generation-inference is a Rust, Python and gRPC server for text generation inference. Used in production at Hugging Face to power Hugging Chat, the Inference API and Inference Endpoint.
vLLM
vLLM is a high-throughput and memory-efficient inference and serving engine for LLMs
2.2 - Heterogeneous Cluster Support
A llama2-7B model can be running on 1xA100 GPU, also on 1xA10 GPU, even on 1x4090 and a variety of other types of GPUs as well, that’s what we called resource fungibility. In practical scenarios, we may have a heterogeneous cluster with different GPU types, and high-end GPUs will stock out a lot, to meet the SLOs of the service as well as the cost, we need to schedule the workloads on different GPU types. With the ResourceFungibility in the InftyAI scheduler, we can simply achieve this with at most 8 alternative GPU types.
How to use
Enable InftyAI scheduler
Edit the values.global.yaml file to modify the following values:
kube-scheduler:
enabled: true
globalConfig:
configData: |-
scheduler-name: inftyai-scheduler
Run make helm-upgrade to install or upgrade llmaz.
2.3 - Distributed Inference
Support multi-host & homogeneous xPyD distributed serving with LWS from day 0. Will implement the heterogeneous xPyD in the future.
3 - Integrations
This section contains the llmaz integration information.
3.1 - Envoy AI Gateway
Envoy AI Gateway is an open source project for using Envoy Gateway
to handle request traffic from application clients to Generative AI services.
How to use
Enable Envoy Gateway and Envoy AI Gateway
Both of them are already enabled by default in values.global.yaml and will be deployed in llmaz-system.
envoy-gateway:
enabled: true
envoy-ai-gateway:
enabled: true
However, Envoy Gateway and Envoy AI Gateway can be deployed standalone in case you want to deploy them in other namespaces.
Basic Example
To expose your models via Envoy Gateway, you need to create a GatewayClass, Gateway, and AIGatewayRoute. The following example shows how to do this.
We’ll deploy two models Qwen/Qwen2-0.5B-Instruct-GGUF and Qwen/Qwen2.5-Coder-0.5B-Instruct-GGUF with llama.cpp (cpu only) and expose them via Envoy AI Gateway.
The full example is here, apply it.
kubectl apply -f https://raw.githubusercontent.com/InftyAI/llmaz/refs/heads/main/docs/examples/envoy-ai-gateway/basic.yaml
Query AI Gateway APIs
If Open-WebUI is enabled, you can chat via the webui (recommended), see documentation. Otherwise, following the steps below to test the Envoy AI Gateway APIs.
I. Port-forwarding the LoadBalancer service in llmaz-system, like:
kubectl -n llmaz-system port-forward \
$(kubectl -n llmaz-system get svc \
-l gateway.envoyproxy.io/owning-gateway-name=default-envoy-ai-gateway \
-o name) \
8080:80
II. Query curl http://localhost:8080/v1/models | jq ., available models will be listed. Expected response will look like this:
{
"data": [
{
"id": "qwen2-0.5b",
"created": 1745327294,
"object": "model",
"owned_by": "Envoy AI Gateway"
},
{
"id": "qwen2.5-coder",
"created": 1745327294,
"object": "model",
"owned_by": "Envoy AI Gateway"
}
],
"object": "list"
}
III. Query http://localhost:8080/v1/chat/completions to chat with the model. Here, we ask the qwen2-0.5b model, the query will look like:
curl -H "Content-Type: application/json" -d '{
"model": "qwen2-0.5b",
"messages": [
{
"role": "system",
"content": "Hi."
}
]
}' http://localhost:8080/v1/chat/completions | jq .
Expected response will look like this:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?"
}
}
],
"created": 1745327371,
"model": "qwen2-0.5b",
"system_fingerprint": "b5124-bc091a4d",
"object": "chat.completion",
"usage": {
"completion_tokens": 10,
"prompt_tokens": 10,
"total_tokens": 20
},
"id": "chatcmpl-AODlT8xnf4OjJwpQH31XD4yehHLnurr0",
"timings": {
"prompt_n": 1,
"prompt_ms": 319.876,
"prompt_per_token_ms": 319.876,
"prompt_per_second": 3.1262114069201816,
"predicted_n": 10,
"predicted_ms": 1309.393,
"predicted_per_token_ms": 130.9393,
"predicted_per_second": 7.63712651587415
}
}
3.2 - Karpenter
Karpenter automatically launches just the right compute resources to handle your cluster’s applications, but it is built to adhere to the scheduling decisions of kube-scheduler, so it’s certainly possible we would run across some cases where Karpenter makes incorrect decisions when the InftyAI scheduler is in the mix.
We forked the Karpenter project and re-complie the karpenter image for cloud providers like AWS, and you can find the details in this proposal. This document provides deployment steps to install and configure Customized Karpenter in an EKS cluster.
How to use
Set environment variables
export KARPENTER_NAMESPACE="kube-system"
export KARPENTER_VERSION="1.5.0"
export K8S_VERSION="1.32"
export AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
export CLUSTER_NAME="${USER}-karpenter-demo"
export AWS_DEFAULT_REGION="us-west-2"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT="$(mktemp)"
export ALIAS_VERSION="$(aws ssm get-parameter --name "/aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2023/x86_64/standard/recommended/image_id" --query Parameter.Value | xargs aws ec2 describe-images --query 'Images[0].Name' --image-ids | sed -r 's/^.*(v[[:digit:]]+).*$/\1/')"
If you open a new shell to run steps in this procedure, you need to set some or all of the environment variables again. To remind yourself of these values, type:
echo "${KARPENTER_NAMESPACE}" "${KARPENTER_VERSION}" "${K8S_VERSION}" "${CLUSTER_NAME}" "${AWS_DEFAULT_REGION}" "${AWS_ACCOUNT_ID}" "${TEMPOUT}" "${ALIAS_VERSION}"
Create a cluster and add Karpenter
Please refer to the Getting Started with Karpenter to create a cluster and add Karpenter.
Install the gpu operator
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v25.3.0
Install llmaz with InftyAI scheduler enabled
Please refer to heterogeneous cluster support.
We need to assign the karpenter-core-llmaz cluster role to the karpenter service account and update the karpenter image to the customized one.
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: karpenter-core-llmaz
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: karpenter-core-llmaz
subjects:
- kind: ServiceAccount
name: karpenter
namespace: ${KARPENTER_NAMESPACE}
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: karpenter-core-llmaz
rules:
- apiGroups: ["llmaz.io"]
resources: ["openmodels"]
verbs: ["get", "list", "watch"]
EOF
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" --create-namespace \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "settings.interruptionQueue=${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait \
--set controller.image.repository=inftyai/karpenter-provider-aws \
--set "controller.image.tag=${KARPENTER_VERSION}" \
--set controller.image.digest=""
Basic Example
- Create a gpu node pool
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: llmaz-demo # you can change the name to a more meaningful one, please align with the node pool's nodeClassRef.
spec:
amiSelectorTerms:
- alias: al2023@${ALIAS_VERSION}
blockDeviceMappings:
# the default volume size of the selected AMI is 20Gi, it is not enough for kubelet to pull
# the images and run the workloads. So we need to map a larger volume to the root device.
# You can change the volume size to a larger value according to your actual needs.
- deviceName: /dev/xvda
ebs:
deleteOnTermination: true
volumeSize: 50Gi
volumeType: gp3
role: KarpenterNodeRole-${CLUSTER_NAME} # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: ${CLUSTER_NAME} # replace with your cluster name
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: ${CLUSTER_NAME} # replace with your cluster name
---
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: llmaz-demo-gpu-nodepool # you can change the name to a more meaningful one.
spec:
disruption:
budgets:
- nodes: 10%
consolidateAfter: 5m
consolidationPolicy: WhenEmptyOrUnderutilized
limits: # You can change the limits to match your actual needs.
cpu: 1000
template:
spec:
expireAfter: 720h
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: llmaz-demo
requirements:
- key: kubernetes.io/arch
operator: In
values:
- amd64
- key: kubernetes.io/os
operator: In
values:
- linux
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- key: karpenter.k8s.aws/instance-family
operator: In
values: # replace with your instance-family with gpu supported
- g4dn
- g5g
taints:
- effect: NoSchedule
key: nvidia.com/gpu
value: "true"
- Deploy a model with flavors
cat <<EOF | kubectl apply -f -
apiVersion: llmaz.io/v1alpha1
kind: OpenModel
metadata:
name: qwen2-0--5b
spec:
familyName: qwen2
source:
modelHub:
modelID: Qwen/Qwen2-0.5B-Instruct
inferenceConfig:
flavors:
# The g5g instance family in the aws cloud can provide the t4g GPU type.
# we define the instance family in the node pool like llmaz-demo-gpu-nodepool.
- name: t4g
limits:
nvidia.com/gpu: 1
# The flavorName is not recongnized by the Karpenter, so we need to specify the
# instance-gpu-name via nodeSelector to match the t4g GPU type when node is provisioned
# by Karpenter from multiple node pools.
#
# When you only have a single node pool to provision the GPU instance and the node pool
# only has one GPU type, it is okay to not specify the nodeSelector. But in practice,
# it is better to specify the nodeSelector to make the provisioned node more predictable.
#
# The available node labels for selecting the target GPU device is listed below:
# karpenter.k8s.aws/instance-gpu-count
# karpenter.k8s.aws/instance-gpu-manufacturer
# karpenter.k8s.aws/instance-gpu-memory
# karpenter.k8s.aws/instance-gpu-name
nodeSelector:
karpenter.k8s.aws/instance-gpu-name: t4g
# The g4dn instance family in the aws cloud can provide the t4 GPU type.
# we define the instance family in the node pool like llmaz-demo-gpu-nodepool.
- name: t4
limits:
nvidia.com/gpu: 1
# The flavorName is not recongnized by the Karpenter, so we need to specify the
# instance-gpu-name via nodeSelector to match the t4 GPU type when node is provisioned
# by Karpenter from multiple node pools.
#
# When you only have a single node pool to provision the GPU instance and the node pool
# only has one GPU type, it is okay to not specify the nodeSelector. But in practice,
# it is better to specify the nodeSelector to make the provisioned node more predictable.
#
# The available node labels for selecting the target GPU device is listed below:
# karpenter.k8s.aws/instance-gpu-count
# karpenter.k8s.aws/instance-gpu-manufacturer
# karpenter.k8s.aws/instance-gpu-memory
# karpenter.k8s.aws/instance-gpu-name
nodeSelector:
karpenter.k8s.aws/instance-gpu-name: t4
---
# Currently, the Playground resource type does not support to configure tolerations
# for the generated pods. But luckily, when a pod with the `nvidia.com/gpu` resource
# is created on the eks cluster, the generated pod will be tweaked with the following
# tolerations:
# - effect: NoExecute
# key: node.kubernetes.io/not-ready
# operator: Exists
# tolerationSeconds: 300
# - effect: NoExecute
# key: node.kubernetes.io/unreachable
# operator: Exists
# tolerationSeconds: 300
# - effect: NoSchedule
# key: nvidia.com/gpu
# operator: Exists
apiVersion: inference.llmaz.io/v1alpha1
kind: Playground
metadata:
labels:
llmaz.io/model-name: qwen2-0--5b
name: qwen2-0--5b
spec:
backendRuntimeConfig:
backendName: tgi
# Due to the limitation of our aws account, we have to decrease the resources to match
# the avaliable instance type which is g4dn.xlarge. If your account has no such limitation,
# you can remove the custom resources settings below.
resources:
limits:
cpu: "2"
memory: 4Gi
requests:
cpu: "2"
memory: 4Gi
modelClaim:
modelName: qwen2-0--5b
replicas: 1
EOF
3.3 - Open-WebUI
Open WebUI is a user-friendly AI interface with OpenAI-compatible APIs, serving as the default chatbot for llmaz.
Prerequisites
How to use
Enable Open WebUI
Open-WebUI is enabled by default in the values.global.yaml and will be deployed in llmaz-system.
open-webui:
enabled: true
Set the Service Address
Run kubectl get svc -n llmaz-system to list out the services, the output looks like below, the LoadBalancer service name will be used later.
envoy-default-default-envoy-ai-gateway-dbec795a LoadBalancer 10.96.145.150 <pending> 80:30548/TCP 132m
envoy-gateway ClusterIP 10.96.52.76 <none> 18000/TCP,18001/TCP,18002/TCP,19001/TCP 172m
Port forward the Open-WebUI service, and visit http://localhost:8080.
kubectl port-forward svc/open-webui 8080:80 -n llmaz-system
Click Settings -> Admin Settings -> Connections, set the URL to http://envoy-default-default-envoy-ai-gateway-dbec795a.llmaz-system.svc.cluster.local/v1 and save. (You can also set the openaiBaseApiUrl in the values.global.yaml)
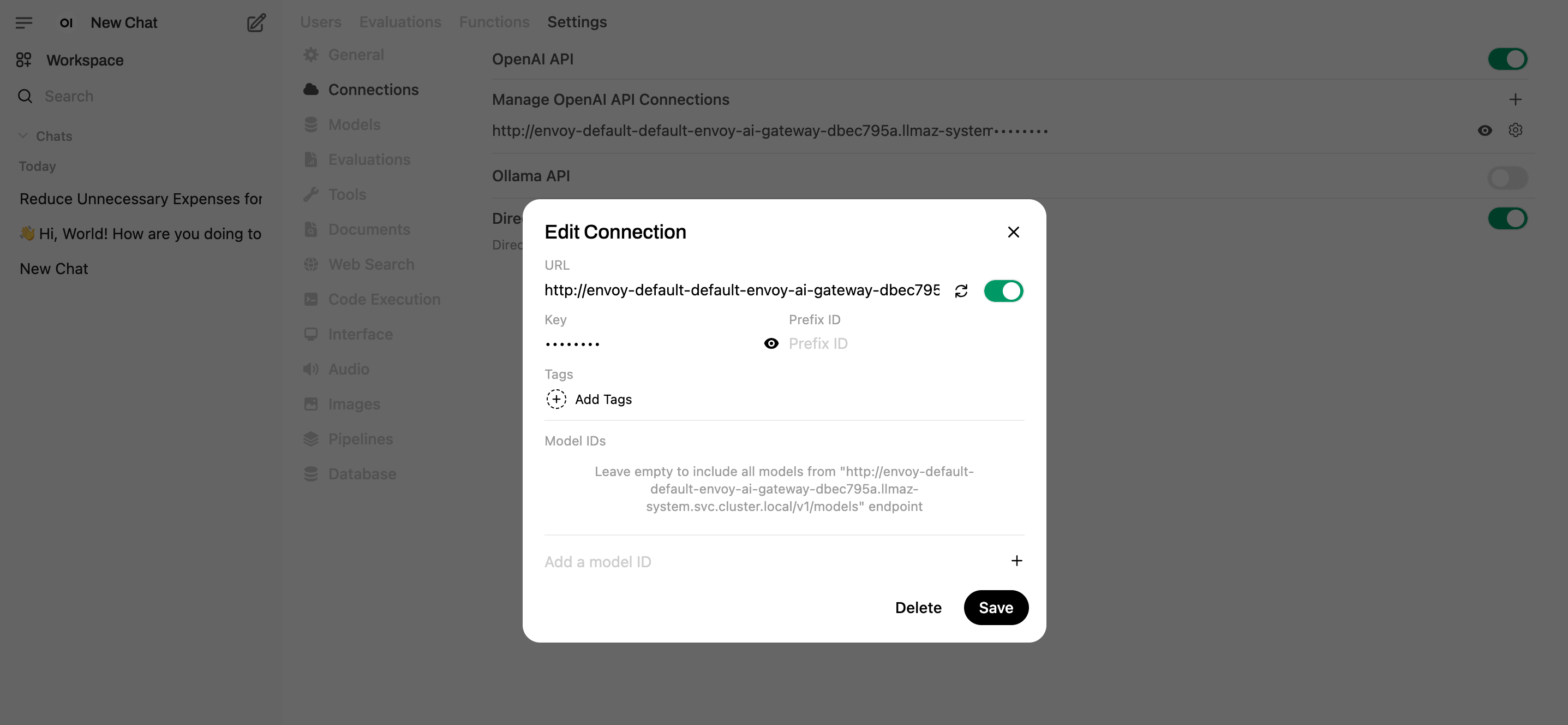
- Start to chat now.
Persistence
Set the persistence=true in values.global.yaml to enable persistence.
3.4 - Prometheus Operator
This document provides deployment steps to install and configure Prometheus Operator in a Kubernetes cluster.
Install the prometheus operator
Please follow the documentation to install prometheus operator or simply run the following command:
curl -sL https://github.com/prometheus-operator/prometheus-operator/releases/download/v0.81.0/bundle.yaml | kubectl create -f -
Ensure that the Prometheus Operator Pod is running successfully.
# Installing the prometheus operator
root@VM-0-5-ubuntu:/home/ubuntu# kubectl get pods
NAME READY STATUS RESTARTS AGE
prometheus-operator-55b5c96cf8-jl2nx 1/1 Running 0 12s
Install the ServiceMonitor CR for llmaz
To enable monitoring for the llmaz system, you need to install the ServiceMonitor custom resource (CR).
You can either modify the Helm chart prometheus according to the documentation or use make install-prometheus in Makefile.
- Using Helm Chart: to modify the values.global.yaml
prometheus:
# -- Whether to enable Prometheus metrics exporting.
enable: true
- Using Makefile Command:
make install-prometheus
root@VM-0-5-ubuntu:/home/ubuntu/llmaz# make install-prometheus
kubectl apply --server-side -k config/prometheus
serviceaccount/llmaz-prometheus serverside-applied
clusterrole.rbac.authorization.k8s.io/llmaz-prometheus serverside-applied
clusterrolebinding.rbac.authorization.k8s.io/llmaz-prometheus serverside-applied
prometheus.monitoring.coreos.com/llmaz-prometheus serverside-applied
servicemonitor.monitoring.coreos.com/llmaz-controller-manager-metrics-monitor serverside-applied
Verify that the necessary resources have been created:
root@VM-0-5-ubuntu:/home/ubuntu/llmaz# kubectl get ServiceMonitor -n llmaz-system
NAME AGE
llmaz-controller-manager-metrics-monitor 59s
root@VM-0-5-ubuntu:/home/ubuntu/llmaz# kubectl get pods -n llmaz-system
NAME READY STATUS RESTARTS AGE
llmaz-controller-manager-7ff8f7d9bd-vztls 2/2 Running 0 28s
prometheus-llmaz-prometheus-0 2/2 Running 0 27s
root@VM-0-5-ubuntu:/home/ubuntu/llmaz# kubectl get svc -n llmaz-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
llmaz-controller-manager-metrics-service ClusterIP 10.96.79.226 <none> 8443/TCP 46s
llmaz-webhook-service ClusterIP 10.96.249.226 <none> 443/TCP 46s
prometheus-operated ClusterIP None <none> 9090/TCP 45s
View metrics using the prometheus UI
Use port forwarding to access the Prometheus UI from your local machine:
root@VM-0-5-ubuntu:/home/ubuntu# kubectl port-forward services/prometheus-operated 9090:9090 --address 0.0.0.0 -n llmaz-system
Forwarding from 0.0.0.0:9090 -> 9090
If using kind, we can use port-forward, kubectl port-forward services/prometheus-operated 39090:9090 --address 0.0.0.0 -n llmaz-system
This allows us to access prometheus using a browser: http://localhost:9090/query
4 - Develop Guidance
This section contains a develop guidance for people who want to learn more about this project.
Project Structure
llmaz # root
├── bin # where the binaries locates, like the kustomize, ginkgo, etc.
├── chart # where the helm chart locates
├── cmd # where the main entry locates
├── docs # where all the documents locate, like examples, installation guidance, etc.
├── llmaz # where the model loader logic locates
├── pkg # where the main logic for Kubernetes controllers locates
API design
Core APIs
See the API Reference for more details.
Inference APIs
See the API Reference for more details.
5 - Reference
This section contains the llmaz reference information.
5.1 - llmaz core API
Generated API reference documentation for llmaz.io/v1alpha1.
Resource Types
OpenModel
Appears in:
OpenModel is the Schema for the open models API
| Field | Description |
|---|
apiVersion
string | llmaz.io/v1alpha1 |
kind
string | OpenModel |
spec [Required]
ModelSpec | No description provided. |
status [Required]
ModelStatus | No description provided. |
Flavor
Appears in:
Flavor defines the accelerator requirements for a model and the necessary parameters
in autoscaling. Right now, it will be used in two places:
- Pod scheduling with node selectors specified.
- Cluster autoscaling with essential parameters provided.
| Field | Description |
|---|
name [Required]
FlavorName | Name represents the flavor name, which will be used in model claim. |
limits
k8s.io/api/core/v1.ResourceList | Limits defines the required accelerators to serve the model for each replica,
like <nvidia.com/gpu: 8>. For multi-hosts cases, the limits here indicates
the resource requirements for each replica, usually equals to the TP size.
Not recommended to set the cpu and memory usage here: - if using playground, you can define the cpu/mem usage at backendConfig.
- if using inference service, you can define the cpu/mem at the container resources.
However, if you define the same accelerator resources at playground/service as well,
the resources will be overwritten by the flavor limit here.
|
nodeSelector
map[string]string | NodeSelector represents the node candidates for Pod placements, if a node doesn't
meet the nodeSelector, it will be filtered out in the resourceFungibility scheduler plugin.
If nodeSelector is empty, it means every node is a candidate. |
params
map[string]string | Params stores other useful parameters and will be consumed by cluster-autoscaler / Karpenter
for autoscaling or be defined as model parallelism parameters like TP or PP size.
E.g. with autoscaling, when scaling up nodes with 8x Nvidia A00, the parameter can be injected
with <INSTANCE-TYPE: p4d.24xlarge> for AWS.
Preset parameters: TP, PP, INSTANCE-TYPE. |
FlavorName
(Alias of string)
Appears in:
InferenceConfig
Appears in:
InferenceConfig represents the inference configurations for the model.
| Field | Description |
|---|
flavors
[]Flavor | Flavors represents the accelerator requirements to serve the model.
Flavors are fungible following the priority represented by the slice order. |
ModelHub
Appears in:
ModelHub represents the model registry for model downloads.
| Field | Description |
|---|
name
string | Name refers to the model registry, such as huggingface. |
modelID [Required]
string | ModelID refers to the model identifier on model hub,
such as meta-llama/Meta-Llama-3-8B. |
filename [Required]
string | Filename refers to a specified model file rather than the whole repo.
This is helpful to download a specified GGUF model rather than downloading
the whole repo which includes all kinds of quantized models.
TODO: this is only supported with Huggingface, add support for ModelScope
in the near future.
Note: once filename is set, allowPatterns and ignorePatterns should be left unset. |
revision
string | Revision refers to a Git revision id which can be a branch name, a tag, or a commit hash. |
allowPatterns
[]string | AllowPatterns refers to files matched with at least one pattern will be downloaded. |
ignorePatterns
[]string | IgnorePatterns refers to files matched with any of the patterns will not be downloaded. |
ModelName
(Alias of string)
Appears in:
ModelRef
Appears in:
ModelRef refers to a created Model with it's role.
| Field | Description |
|---|
name [Required]
ModelName | Name represents the model name. |
role
ModelRole | Role represents the model role once more than one model is required.
Such as a draft role, which means running with SpeculativeDecoding,
and default arguments for backend will be searched in backendRuntime
with the name of speculative-decoding. |
ModelRole
(Alias of string)
Appears in:
ModelSource
Appears in:
ModelSource represents the source of the model.
Only one model source will be used.
| Field | Description |
|---|
modelHub
ModelHub | ModelHub represents the model registry for model downloads. |
uri
URIProtocol | URI represents a various kinds of model sources following the uri protocol, protocol://, e.g. - oss://./
- ollama://llama3.3
- host://
|
ModelSpec
Appears in:
ModelSpec defines the desired state of Model
| Field | Description |
|---|
familyName [Required]
ModelName | FamilyName represents the model type, like llama2, which will be auto injected
to the labels with the key of llmaz.io/model-family-name. |
source [Required]
ModelSource | Source represents the source of the model, there're several ways to load
the model such as loading from huggingface, OCI registry, s3, host path and so on. |
inferenceConfig [Required]
InferenceConfig | InferenceConfig represents the inference configurations for the model. |
ownedBy
string | OwnedBy represents the owner of the running models serving by the backends,
which will be exported as the field of "OwnedBy" in openai-compatible API "/models".
Default to "llmaz" if not set. |
createdAt
k8s.io/apimachinery/pkg/apis/meta/v1.Time | CreatedAt represents the creation timestamp of the running models serving by the backends,
which will be exported as the field of "Created" in openai-compatible API "/models".
It follows the format of RFC 3339, for example "2024-05-21T10:00:00Z". |
ModelStatus
Appears in:
ModelStatus defines the observed state of Model
URIProtocol
(Alias of string)
Appears in:
URIProtocol represents the protocol of the URI.
5.2 - llmaz inference API
Generated API reference documentation for inference.llmaz.io/v1alpha1.
Resource Types
Playground
Appears in:
Playground is the Schema for the playgrounds API
| Field | Description |
|---|
apiVersion
string | inference.llmaz.io/v1alpha1 |
kind
string | Playground |
spec [Required]
PlaygroundSpec | No description provided. |
status [Required]
PlaygroundStatus | No description provided. |
Service
Appears in:
Service is the Schema for the services API
| Field | Description |
|---|
apiVersion
string | inference.llmaz.io/v1alpha1 |
kind
string | Service |
spec [Required]
ServiceSpec | No description provided. |
status [Required]
ServiceStatus | No description provided. |
BackendName
(Alias of string)
Appears in:
BackendRuntime
Appears in:
BackendRuntime is the Schema for the backendRuntime API
BackendRuntimeConfig
Appears in:
| Field | Description |
|---|
backendName
BackendName | BackendName represents the inference backend under the hood, e.g. vLLM. |
version
string | Version represents the backend version if you want a different one
from the default version. |
envs
[]k8s.io/api/core/v1.EnvVar | Envs represents the environments set to the container. |
configName [Required]
string | ConfigName represents the recommended configuration name for the backend,
It will be inferred from the models in the runtime if not specified, e.g. default,
speculative-decoding. |
args
[]string | Args defined here will "append" the args defined in the recommendedConfig,
either explicitly configured in configName or inferred in the runtime. |
resources
ResourceRequirements | Resources represents the resource requirements for backend, like cpu/mem,
accelerators like GPU should not be defined here, but at the model flavors,
or the values here will be overwritten.
Resources defined here will "overwrite" the resources in the recommendedConfig. |
sharedMemorySize
k8s.io/apimachinery/pkg/api/resource.Quantity | SharedMemorySize represents the size of /dev/shm required in the runtime of
inference workload.
SharedMemorySize defined here will "overwrite" the sharedMemorySize in the recommendedConfig. |
BackendRuntimeSpec
Appears in:
BackendRuntimeSpec defines the desired state of BackendRuntime
| Field | Description |
|---|
command
[]string | Command represents the default command for the backendRuntime. |
image [Required]
string | Image represents the default image registry of the backendRuntime.
It will work together with version to make up a real image. |
version [Required]
string | Version represents the default version of the backendRuntime.
It will be appended to the image as a tag. |
envs
[]k8s.io/api/core/v1.EnvVar | Envs represents the environments set to the container. |
lifecycle
k8s.io/api/core/v1.Lifecycle | Lifecycle represents hooks executed during the lifecycle of the container. |
livenessProbe
k8s.io/api/core/v1.Probe | Periodic probe of backend liveness.
Backend will be restarted if the probe fails.
Cannot be updated. |
readinessProbe
k8s.io/api/core/v1.Probe | Periodic probe of backend readiness.
Backend will be removed from service endpoints if the probe fails. |
startupProbe
k8s.io/api/core/v1.Probe | StartupProbe indicates that the Backend has successfully initialized.
If specified, no other probes are executed until this completes successfully.
If this probe fails, the backend will be restarted, just as if the livenessProbe failed.
This can be used to provide different probe parameters at the beginning of a backend's lifecycle,
when it might take a long time to load data or warm a cache, than during steady-state operation. |
recommendedConfigs
[]RecommendedConfig | RecommendedConfigs represents the recommended configurations for the backendRuntime. |
BackendRuntimeStatus
Appears in:
BackendRuntimeStatus defines the observed state of BackendRuntime
ElasticConfig
Appears in:
| Field | Description |
|---|
minReplicas
int32 | MinReplicas indicates the minimum number of inference workloads based on the traffic.
Default to 1.
MinReplicas couldn't be 0 now, will support serverless in the future. |
maxReplicas [Required]
int32 | MaxReplicas indicates the maximum number of inference workloads based on the traffic.
Default to nil means there's no limit for the instance number. |
scaleTrigger
ScaleTrigger | ScaleTrigger defines the rules to scale the workloads.
Only one trigger cloud work at a time, mostly used in Playground.
ScaleTrigger defined here will "overwrite" the scaleTrigger in the recommendedConfig. |
HPATrigger
Appears in:
HPATrigger represents the configuration of the HorizontalPodAutoscaler.
Inspired by kubernetes.io/pkg/apis/autoscaling/types.go#HorizontalPodAutoscalerSpec.
Note: HPA component should be installed in prior.
| Field | Description |
|---|
metrics
[]k8s.io/api/autoscaling/v2.MetricSpec | metrics contains the specifications for which to use to calculate the
desired replica count (the maximum replica count across all metrics will
be used). The desired replica count is calculated multiplying the
ratio between the target value and the current value by the current
number of pods. Ergo, metrics used must decrease as the pod count is
increased, and vice-versa. See the individual metric source types for
more information about how each type of metric must respond. |
behavior
k8s.io/api/autoscaling/v2.HorizontalPodAutoscalerBehavior | behavior configures the scaling behavior of the target
in both Up and Down directions (scaleUp and scaleDown fields respectively).
If not set, the default HPAScalingRules for scale up and scale down are used. |
PlaygroundSpec
Appears in:
PlaygroundSpec defines the desired state of Playground
| Field | Description |
|---|
replicas
int32 | Replicas represents the replica number of inference workloads. |
modelClaim
ModelClaim | ModelClaim represents claiming for one model, it's a simplified use case
of modelClaims. Most of the time, modelClaim is enough.
ModelClaim and modelClaims are exclusive configured. |
modelClaims
ModelClaims | ModelClaims represents claiming for multiple models for more complicated
use cases like speculative-decoding.
ModelClaims and modelClaim are exclusive configured. |
backendRuntimeConfig
BackendRuntimeConfig | BackendRuntimeConfig represents the inference backendRuntime configuration
under the hood, e.g. vLLM, which is the default backendRuntime. |
elasticConfig
ElasticConfig | ElasticConfig defines the configuration for elastic usage,
e.g. the max/min replicas. |
PlaygroundStatus
Appears in:
PlaygroundStatus defines the observed state of Playground
| Field | Description |
|---|
conditions [Required]
[]k8s.io/apimachinery/pkg/apis/meta/v1.Condition | Conditions represents the Inference condition. |
replicas [Required]
int32 | Replicas track the replicas that have been created, whether ready or not. |
selector [Required]
string | Selector points to the string form of a label selector which will be used by HPA. |
RecommendedConfig
Appears in:
RecommendedConfig represents the recommended configurations for the backendRuntime,
user can choose one of them to apply.
| Field | Description |
|---|
name [Required]
string | Name represents the identifier of the config. |
args
[]string | Args represents all the arguments for the command.
Argument around with {{ .CONFIG }} is a configuration waiting for render. |
resources
ResourceRequirements | Resources represents the resource requirements for backend, like cpu/mem,
accelerators like GPU should not be defined here, but at the model flavors,
or the values here will be overwritten. |
sharedMemorySize
k8s.io/apimachinery/pkg/api/resource.Quantity | SharedMemorySize represents the size of /dev/shm required in the runtime of
inference workload. |
scaleTrigger
ScaleTrigger | ScaleTrigger defines the rules to scale the workloads.
Only one trigger cloud work at a time. |
ResourceRequirements
Appears in:
TODO: Do not support DRA yet, we can support that once needed.
| Field | Description |
|---|
limits
k8s.io/api/core/v1.ResourceList | Limits describes the maximum amount of compute resources allowed.
More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
requests
k8s.io/api/core/v1.ResourceList | Requests describes the minimum amount of compute resources required.
If Requests is omitted for a container, it defaults to Limits if that is explicitly specified,
otherwise to an implementation-defined value. Requests cannot exceed Limits.
More info: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
ScaleTrigger
Appears in:
ScaleTrigger defines the rules to scale the workloads.
Only one trigger cloud work at a time, mostly used in Playground.
| Field | Description |
|---|
hpa [Required]
HPATrigger | HPA represents the trigger configuration of the HorizontalPodAutoscaler. |
ServiceSpec
Appears in:
ServiceSpec defines the desired state of Service.
Service controller will maintain multi-flavor of workloads with
different accelerators for cost or performance considerations.
| Field | Description |
|---|
modelClaims [Required]
ModelClaims | ModelClaims represents multiple claims for different models. |
replicas
int32 | Replicas represents the replica number of inference workloads. |
workloadTemplate [Required]
sigs.k8s.io/lws/api/leaderworkerset/v1.LeaderWorkerTemplate | WorkloadTemplate defines the template for leader/worker pods |
rolloutStrategy
sigs.k8s.io/lws/api/leaderworkerset/v1.RolloutStrategy | RolloutStrategy defines the strategy that will be applied to update replicas
when a revision is made to the leaderWorkerTemplate. |
ServiceStatus
Appears in:
ServiceStatus defines the observed state of Service
| Field | Description |
|---|
conditions [Required]
[]k8s.io/apimachinery/pkg/apis/meta/v1.Condition | Conditions represents the Inference condition. |
replicas [Required]
int32 | Replicas track the replicas that have been created, whether ready or not. |
selector [Required]
string | Selector points to the string form of a label selector, the HPA will be
able to autoscale your resource. |